In an article that I published nearly two years ago titled Are Humans Actually Underrated, I talked about how technology can be used to augment human intelligence to empower humans to work better, smarter and faster.

The notion that technology can enhance human capabilities is far from novel. Often termed Intelligence Augmentation, Intelligence Amplification, Cognitive Augmentation, or Machine Augmented Intelligence, this concept revolves around leveraging information technology to bolster human intellect. Its roots trace back to the 1950s and 60s, a testament to its enduring relevance.
From the humble mouse and graphical user interface to the ubiquitous iPhone and the cutting-edge advancements in Artificial Intelligence like ChatGPT, Intelligence Augmentation has been steadily evolving. These tools and platforms serve as tangible examples of how technology can be harnessed to augment our cognitive abilities and propel us towards greater efficiency and innovation.
An area of scientific development closely aligned with Intelligence Augmentation is the field of Causal Reasoning. Before diving into this, it’s essential to underscore the fundamental importance of causality. Understanding why things happen, not just what happened, is the cornerstone of effective problem-solving, decision-making, and innovation.
Humans Crave Causality
Our innate curiosity drives us to seek explanations for the world around us. This deep-rooted desire to understand cause-and-effect relationships is fundamental to human cognition. Here’s why:
Survival: At the most basic level it all boils down to survival. By understanding cause-and-effect, we can learn what actions lead to positive outcomes (food, shelter, safety) and avoid negative ones (danger, illness, death).
Learning: Understanding cause-and-effect is fundamental to learning and acquiring knowledge. We learn by observing and making connections between events, forming a mental model of how the world works.
Prediction: Being able to predict what will happen allows us to plan for the future and make informed choices. We can anticipate the consequences of our actions and prepare for them.
Problem-solving: Cause-and-effect is crucial for solving problems efficiently. By identifying the cause of an issue, we can develop solutions that address the root cause rather than just treating the symptoms.
Scientific Discovery: This innate desire to understand causality drives scientific inquiry. By seeking cause-and-effect relationships, we can unravel the mysteries of the universe and develop new technologies.
Technological Advancement: Technology thrives on our ability to understand cause-and-effect. From inventing tools to building machines, understanding how things work allows us to manipulate the world around us.
Societal Progress: When we understand the causes of social issues, we can develop solutions to address them. Understanding cause-and-effect fosters cooperation and allows us to build a better future for ourselves and future generations.
Understanding Cause & Effect In The Digital World
In the complex digital age, this craving for causality remains as potent as ever. Nowhere is this more evident than in the world of cloud native applications. These intricate systems, composed of interconnected microservices and distributed components, can be challenging to manage and troubleshoot. When things go wrong, pinpointing the root cause can be akin to searching for a needle in a haystack.
 This is increasingly important today because so many businesses rely on modern applications and real time data to conduct their daily business. Delays, missing data and malfunctions can have a crippling effect on business processes and customer experiences which in turn can have significant financial consequences.
This is increasingly important today because so many businesses rely on modern applications and real time data to conduct their daily business. Delays, missing data and malfunctions can have a crippling effect on business processes and customer experiences which in turn can have significant financial consequences.
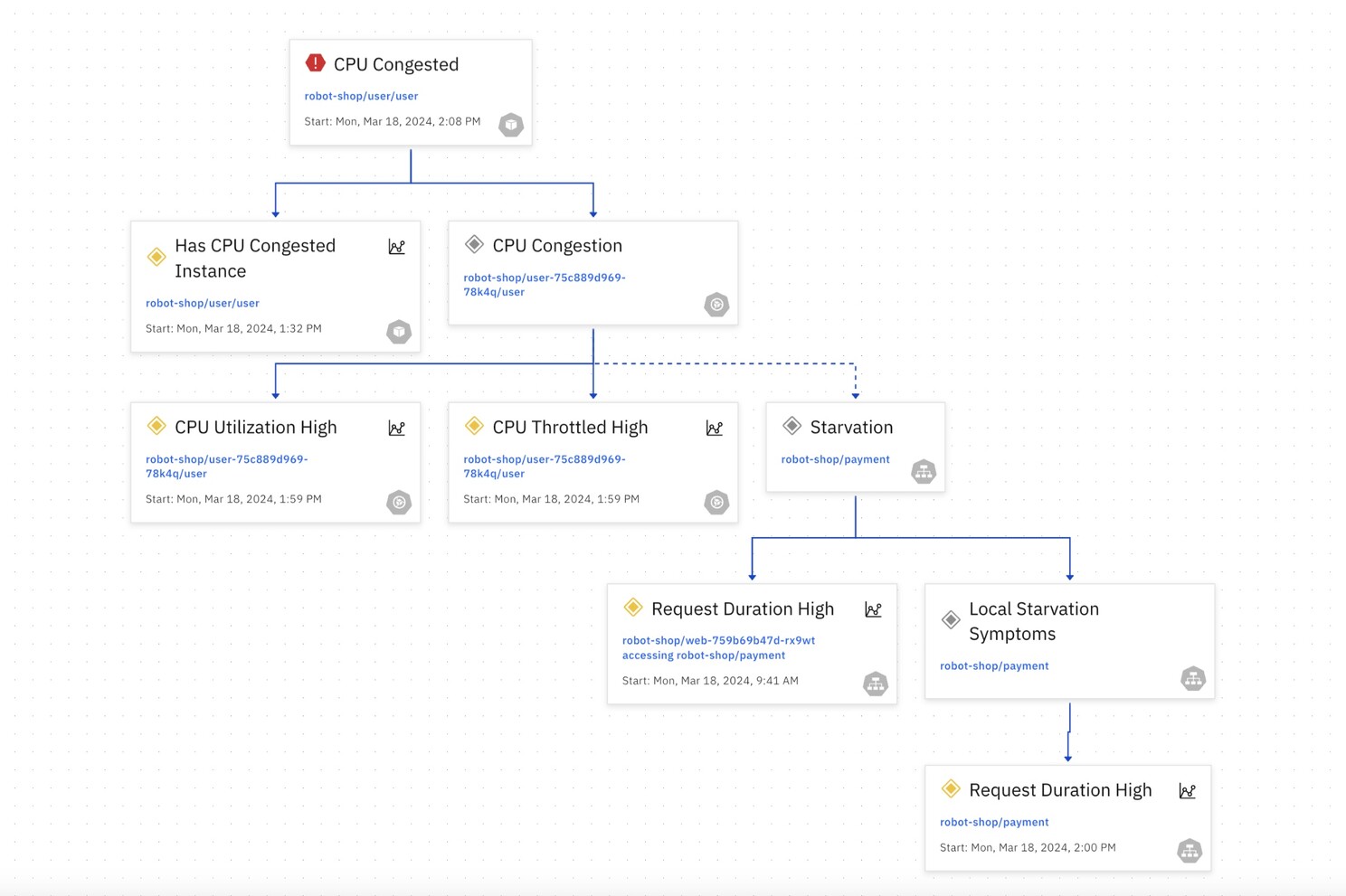
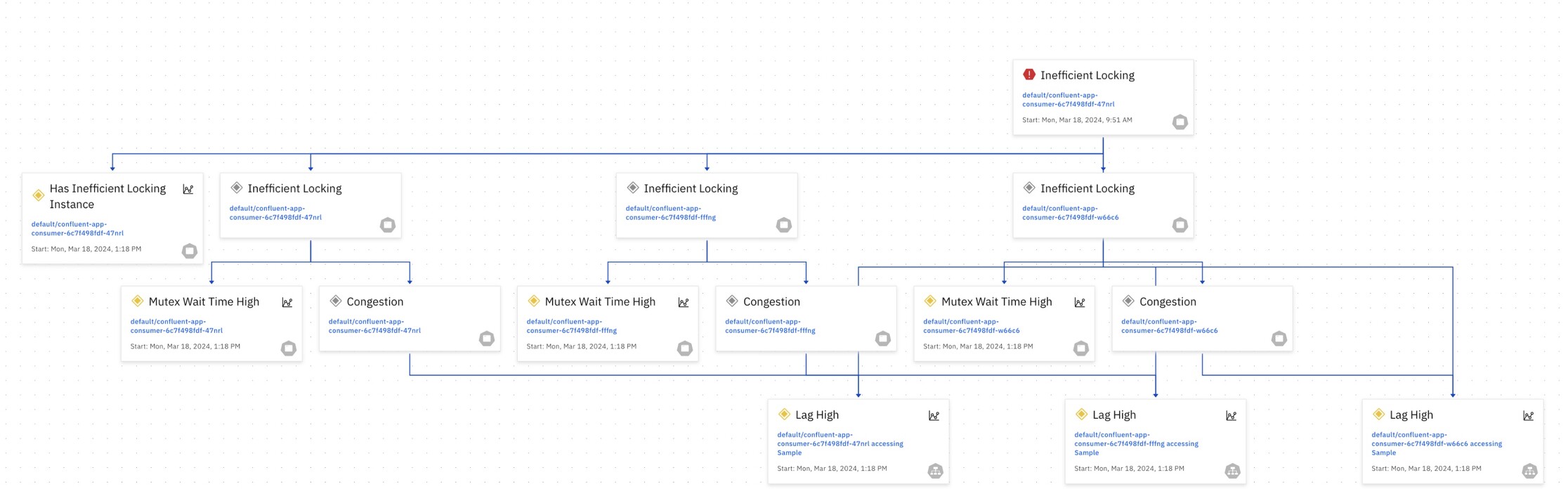
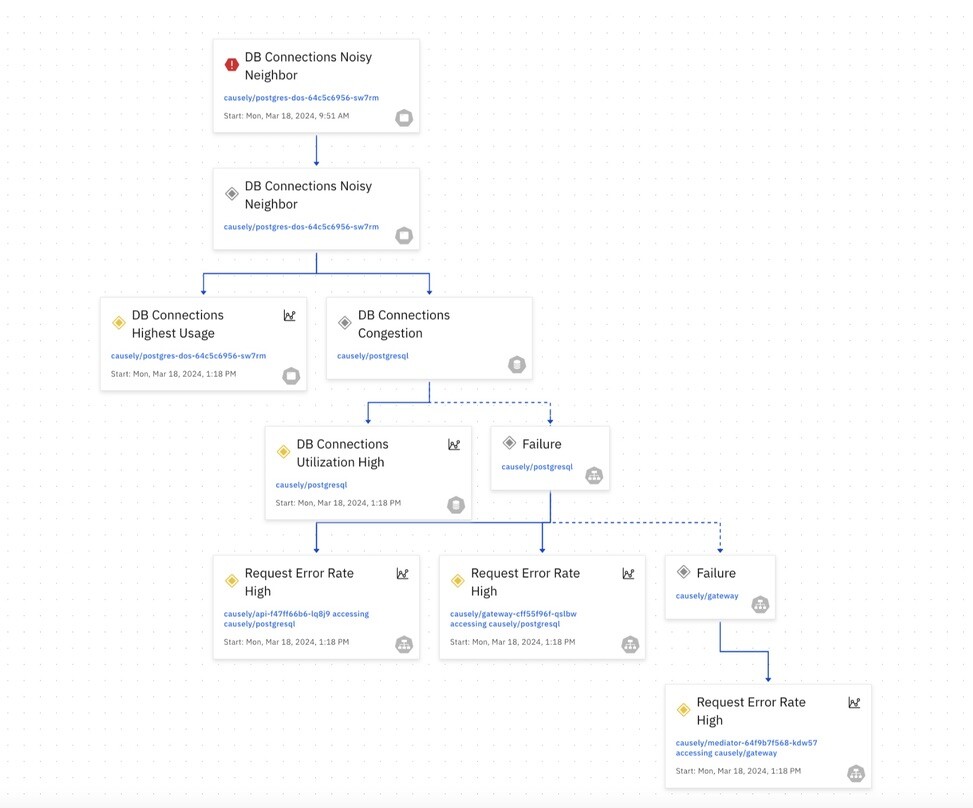
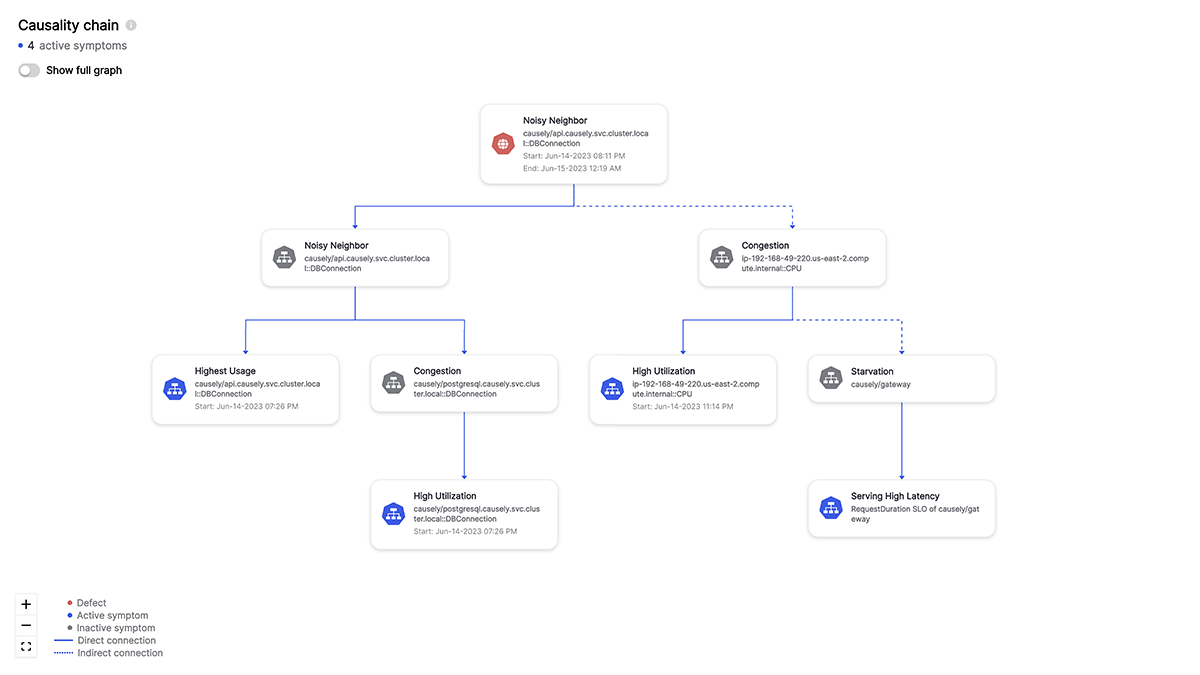
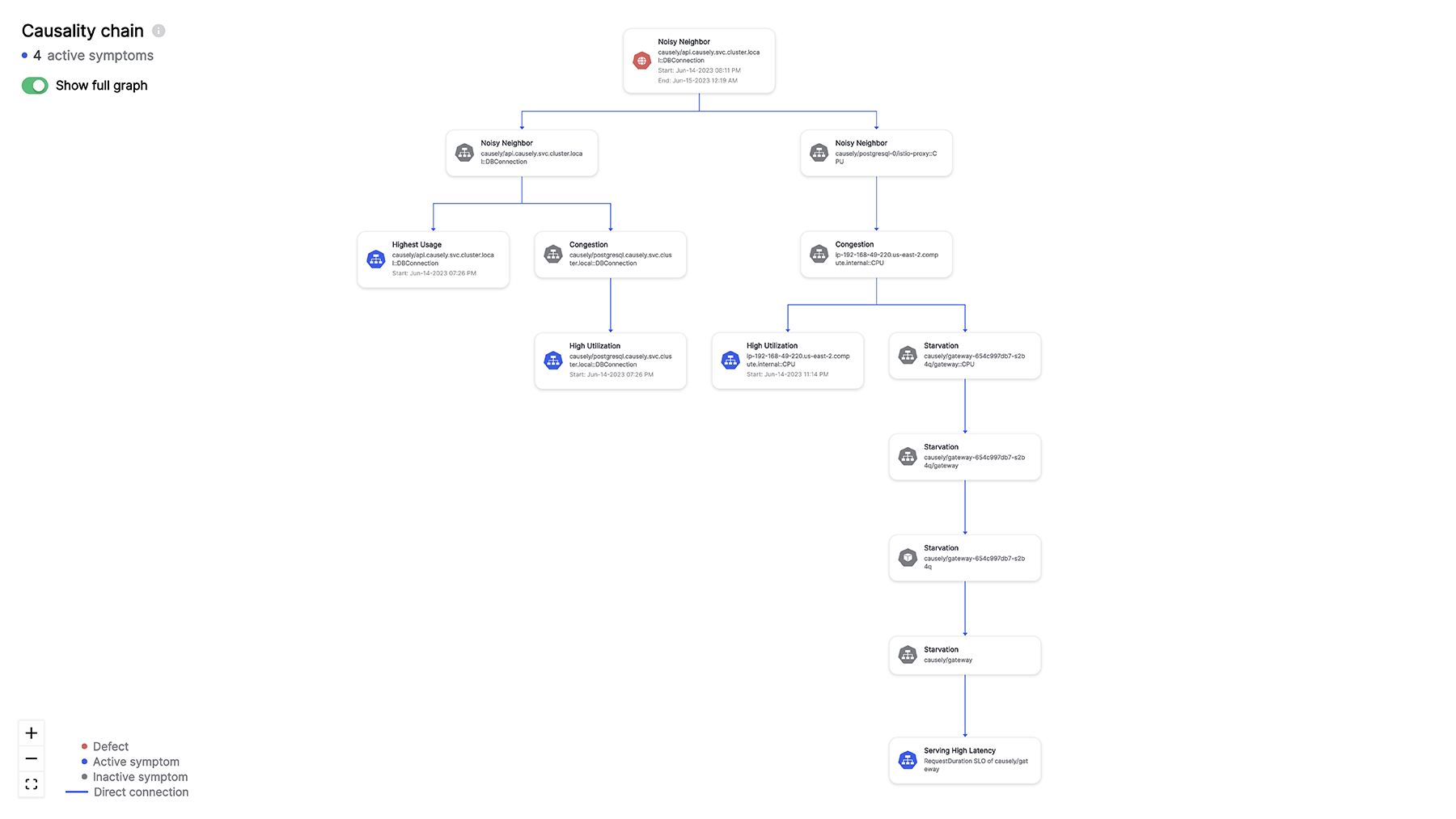
Understanding causality in this context is paramount. It’s the difference between reacting to symptoms and addressing the underlying issue. For instance, a sudden spike in error rates might be attributed to increased traffic. While this might be a contributing factor, the root cause could lie in a misconfigured database, a network latency issue, or a bug in a specific microservice. Without a clear understanding of the causal relationships between these components, resolving the problem becomes a matter of trial and error.
Today site reliability engineers (SREs) and developers, tasked with ensuring the reliability and performance of cloud native systems, rely heavily on causal reasoning. They do this by constructing mental models of how different system components interact, they attempt to anticipate potential failure points and develop strategies to mitigate risks.
When incidents occur, SREs and developers work together, employing a systematic approach to identify the causal chain, from the initial trigger to the eventual impact on users. We rely heavily on their knowledge to implement effective remediation steps and prevent future occurrences.

In the intricate world of cloud native applications, where complexity reigns, this innate ability to connect cause and effect is essential for building resilient, high-performing systems.
The Crucial Role of Observability in Understanding Causality in Cloud Native Systems
OpenTelemetry and its ecosystem of observability tools provide a window into the complex world of cloud native systems. By collecting and analyzing vast amounts of data, engineers can gain valuable insights into system behavior. However, understanding why something happened – establishing causality – still remains a significant challenge.
The inability to rapidly pinpoint the root cause of issues is a costly affair. A recent PagerDuty customer survey revealed that the average time to resolve digital incidents is a staggering 175 minutes. This delay impacts service reliability, erodes customer satisfaction, revenue and consumes lots of engineering cycles in the process. A time-consuming process often leaves engineering teams overwhelmed and firefighting.

To drive substantial improvements in system reliability and performance, organizations must accelerate their ability to understand causality. This requires a fundamental shift in how we approach observability. By investing in advanced analytics that can reason about causality, we can empower engineers to quickly identify root causes and their effects so they can prioritize what is important and implement effective solutions.
Augmenting Human Ingenuity with Causal Reasoning
In this regard, causal reasoning software like Causely represent a quantum leap forward in the evolution of human-machine collaboration. By combining this capability with OpenTelemetry, the arduous task of causal reasoning can be automated, liberating SREs and developers from the firefighting cycle. Instead of being perpetually mired in troubleshooting, they can dedicate more cognitive resources to innovation and strategic problem-solving.
Imagine these professionals equipped with the ability to process vast quantities of observability data in mere seconds, unveiling intricate causal relationships that would otherwise remain hidden. This is the power of causal reasoning software that is built to amplify the processes associated with Reliability Engineering. They amplify human intelligence, transforming SREs and developers from reactive problem solvers into proactive architects of system reliability.
By accelerating incident resolution from today’s averages (175 minutes as documented in the PagerDuty’s customer survey) to mere minutes, these platforms not only enhance customer satisfaction but also unlock significant potential for business growth. With freed-up time, teams can focus on developing new features, improving system performance, and preventing future issues. Moreover, the insights derived from causal reasoning software can be leveraged to proactively identify vulnerabilities and optimize system performance, elevating the overall reliability and resilience of cloud native architectures.
The convergence of human ingenuity and machine intelligence, embodied in causal reasoning software, is ushering in a new era of problem-solving. This powerful combination enables us to tackle unprecedented challenges with unparalleled speed, accuracy, and innovation.
In the context of reliability engineering, the combination of OpenTelemetry and causal reasoning software offers a significant opportunity to accelerate progress towards continuous application reliability.
Related resources
- Read the blog: Explainability: The Black Box Dilemma in the Real World
- Watch the video: See how Causely leverages OpenTelemetry
- Take the interactive tour: Experience Causely first-hand