
Sisyphus. Source: https://commons.wikimedia.org/wiki/File:Punishment_sisyph.jpg
This blog was originally posted on LinkedIn.
How causality can eliminate human troubleshooting
Tasks that are both laborious and futile are described as Sisyphean. In Greek mythology, Sisyphus was the founder and king of Ephyra (now known as Corinth). Hades – the king of the underworld – punished him for cheating death twice by forcing him to roll an immense boulder up a hill only for it to roll back down every time it neared the top, repeating this action for eternity.
The goal of application support engineers is to identify, detect, remediate, and prevent failures or violations of service level objectives (SLOs). DevOps have been pronounced dead by some, but still seem to be tasked with building and running apps at scale. Observability tools provide comprehensive monitoring, proactive alerting, anomaly detection, and maybe even some automation of routine tasks, such as scaling resources. But they leave the Sisyphean heavy lifting job of troubleshooting, incident response and remediation, as well as root cause analysis and continuous improvements during or after an outage, to humans.
Businesses are changing rapidly; application management has to change
Today’s environments are highly dynamic. Businesses must be able to rapidly adjust their operations, scale resources, deliver sophisticated services, facilitate seamless interactions, and adapt quickly to changing market conditions.
The scale and complexity of application environments is expanding continuously. Application architectures are increasingly complex, with organizations relying on a larger number of cloud services from multiple providers. There are more systems to troubleshoot and optimize, and more data points to keep track of. Data is growing exponentially across all technology domains affecting its collection, transport, storage, and analysis. Application management relies on technologies that try to capture this growing complexity and volume, but those technologies are limited by the fact that they’re based on data and models that assume that the future will look a lot like the past. This approach can be effective in relatively static environments where patterns and relationships remain consistent over time. However, in today’s rapidly changing environments, this will fail.
As a result, application support leaders find it increasingly difficult to manage the increasing complexity and growing volume of data in cloud-native technology stacks. Operating dynamic application environments is simply beyond human scale, especially in real time. The continuous growth of data generated by user interactions, cloud instances, and containers requires a shift in mindset and management approaches.
Relationships between applications and infrastructure components are complex and constantly changing
A major reason that relationships and related entities are constantly changing is because of the complicated and dynamic nature of application and infrastructure components. Creating a new container and destroying it takes seconds to minutes each time, and with every change includes changes to tags, labels, and metrics. This demonstrates the sheer volume, cardinality, and complexity of observability datasets.
The complexity and constant change within application environments is why it can take days to figure out what is causing a problem. It’s hard to capture causality in a dataset that’s constantly changing based on new sets of applications, new databases, new infrastructure, new software versions, etc. As soon as you identify one correlation, the landscape has likely already changed.

Correlation is not causation. Source: https://twitter.com/OdedRechavi/status/1442759942553968640/photo/1
Correlation is NOT causation
The most common trap that people fall into is assuming correlation equals causation. Correlation and causation both indicate a relationship exists between two occurrences, but correlation is non-directional, while causation implies direction. In other words, causation concludes that one occurrence was the consequence of another occurrence.
It’s important to clearly distinguish correlation from causation before jumping to any conclusions. Neither pattern identification nor trend identification is causation. Even if you apply correlation on top of an identified trend, you won’t get the root cause. Without causality, you cannot understand the root cause of a set of observations and without the root cause, the problem cannot be resolved or prevented in the future.
Blame the network. Source @ioshints
Don’t assume that all application issues are caused by infrastructure
In application environments, the conflation between correlation and causation often manifests through assumptions that symptoms propagate on a predefined path – or, to be more specific, that all application issues stem from infrastructure limitations or barriers. How many times have you heard that it is always “the network’s fault”?
In a typical microservices environment, application support teams will start getting calls and alerts about various clients experiencing high latency, which will also lead to the respective SLOs being violated. These symptoms can be caused by increased traffic, inefficient algorithms, misconfigured or insufficient resources or noisy neighbors in a shared environment. Identifying the root cause across multiple layers of the stack, typically managed by different application and infrastructure teams, can be incredibly difficult. It requires not just observability data including logs, metrics, time-series anomalies, and topological relationships, but also the causality knowledge to reason if this is an application problem impacting the infrastructure vs. an infrastructure problem impacting the applications, or even applications and microservices impacting each other.
Capture knowledge, not just data
Gathering more data points about every aspect of an application environment will not enable you to learn causality – especially in a highly dynamic application environment. Causation can’t be learned only by observing data or generating more alerts. It can be validated or enhanced as you get data, but you shouldn’t start there.
Think failures/defects, not alerts
Start by thinking about failures/defects instead of the alerts or symptoms that are being observed. Failures require intervention and either recur or currently cannot be resolved. Only when you know the failures you care about should you look at the alerts or symptoms that may be caused by them.
Root cause analysis (RCA) is the problem of inferring failures from an observed set of symptoms. For example, bad choices of algorithms or data structures may cause service latency, high CPU or high memory utilization as observed symptoms and alerts. The root cause of bad choices of algorithms and data structures can be inferred from the observed symptoms.
Causal AI is required to solve the RCA problem
Causal AI is an artificial intelligence system that can explain cause and effect. Unlike predictive AI models that are based on historical data, systems based on causal AI provide insight by identifying the underlying web of causality for a given behavior or event. The concept of causal AI and the limits of machine learning were raised by Judea Pearl, the Turing Award-winning computer scientist and philosopher, in The Book of Why: The New Science of Cause and Effect.
“Machines’ lack of understanding of causal relations is perhaps the biggest roadblock to giving them human-level intelligence.”
– Judea Pearl, The Book of Why
Causal graphs are the best illustration of causal AI implementations. A causal graph is a visual representation that usually shows arrows to indicate causal relationships between different events across multiple entities.
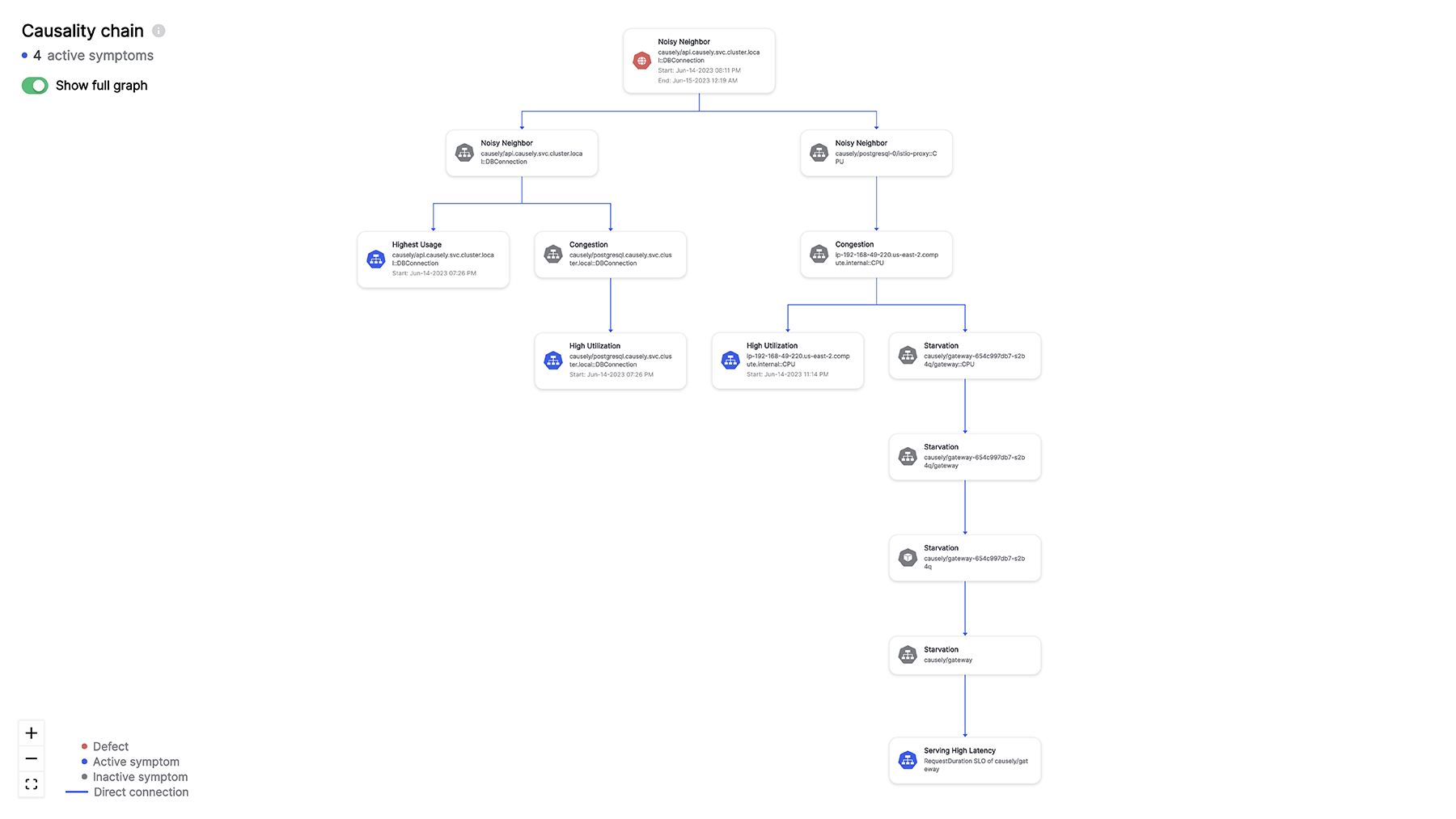
Database Noisy Neighbor causing service and infrastructure symptoms
In this example, we are observing multiple clients experiencing errors and service latency, as well as neighboring microservices suffering from not getting enough compute resources. Any attempt to tackle the symptoms independently, by for instance increasing CPU limit, or horizontal scaling the impacted service, will not solve the REAL problem.
The best explanation for this combination of observed symptoms is the problem with the application’s interaction with the database. The root cause can be inferred even when not all the symptoms are observed. Instead of troubleshooting individual client errors or infrastructure symptoms, the application support team can focus on the root cause and fix the application.
Capturing this human knowledge in a declarative form allows causal AI to reason about not just the observed symptoms but also the missing symptoms in the context of the causality propagations between application and infrastructure events. You need to have a structured way of capturing the knowledge that already exists in the minds and experiences of application support teams.
Wrapping up
Hopefully this blog helps you to begin to think about causality and how you can capture your own knowledge in causality chains like the one above. Human troubleshooting needs to be relegated to history and replaced with automated causality systems.
This is something we think about a lot at Causely, and would love any feedback or commentary about your own experiences trying to solve these kinds of problems.
Related resources
- Read the blog: One million ways to slow down your application response time and throughput
- Learn about Causely’s causal AI platform for IT
- Get early access to Causely for cloud-native applications